Я заметил, что если поднять количество источников в веб-поиске, то полезность локальной Gemma 3 существенно возрастает. Всё-таки главный недостаток слабой модели в том, что она мало знает, но если дать ей искать, в целом ряде вопросов этот недостаток можно сократить. Конечно, она не сравнится с большой нейросетью, но учитывая смешные требования к оборудованию, отношение пользы к затраченным ресурсам получается впечатляющее.
Ollama теперь обновляется почти каждый день, и в текущей версии 0.9.0 впилили поддержку режима рассуждения (thinking mode), сходу же была обновлена модель DeepSeek для Ollama, которая теперь его поддерживает на этой версии. До этого в основном фиксили баги и вносили мелкие правки. DeepSeek тяжеловата, я всё ещё жду (хоть об этом никто и не объявлял), что релизнут новую Gemma 3n, где будет настоящая мультимодальность, а требования к ресурсам - ещё ниже. Надеюсь, такой релиз будет и эта Джемма не останется "эксклюзивом" AI Studio и её реально можно будет крутить локально (а ради этого вроде как она и существует, в отличие от большой Gemini).
Я же пытался с помощью DeepSeek сгенерировать движок для блога на PHP, чтобы посмотреть, как он справится с такой задачей.
Думаю, вы уже догадались, что...
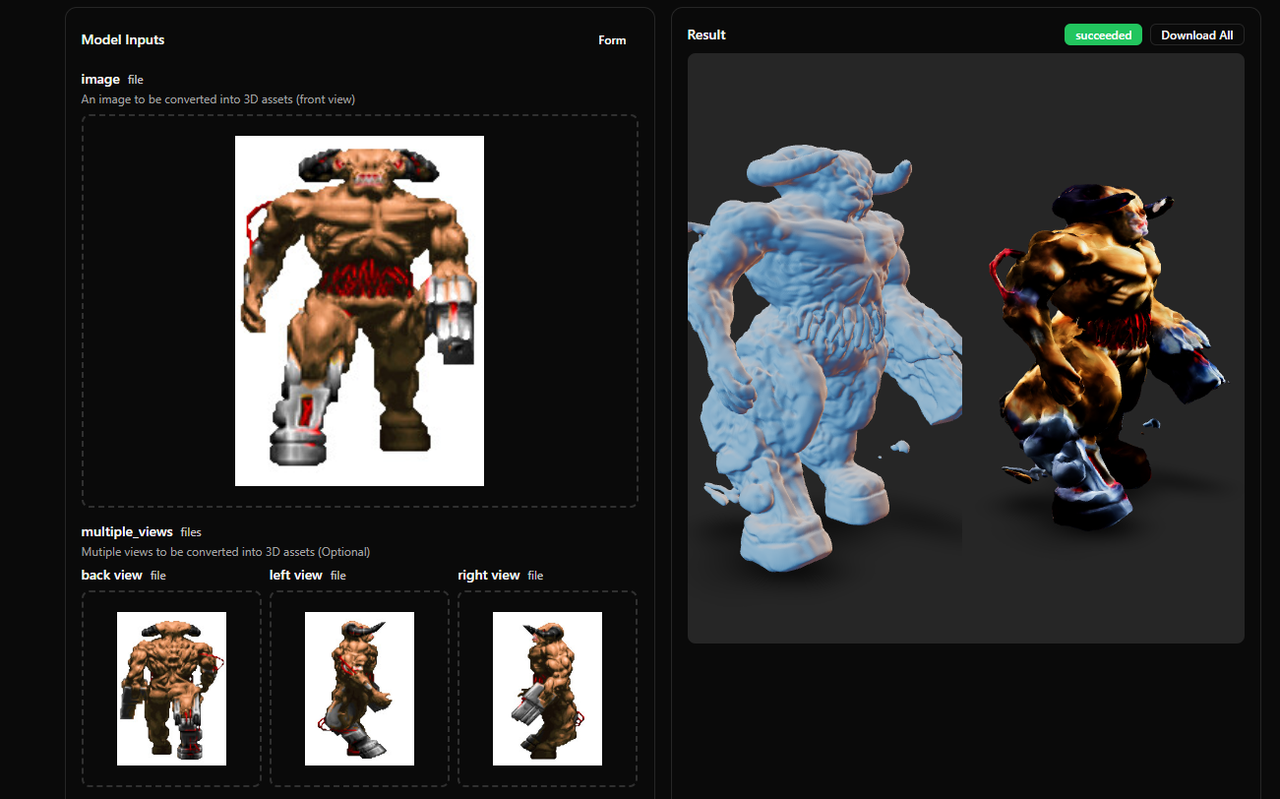
lafoxxx [B0S], хорошо получилась грудь и провода на животе, а мелкие детали, голова и конечности не очень. Думаю, из-за мелкого разрешения и пиксельности нейросеть просто не поняла, где и какие детали прорисовывать. А в целом, да, неплохо.
Не знаю, как там грудь и волосы на груди кибердемона,
но свеженаписанные на ютубе песни Виктора Цоя мне нравятся!
Ощутимо хуже и невнятнее оригинала, но что-то в этом есть! - особенно когда идёт на фоне анимированной картинки!
Оригинал всё же лучше, я не совсем сумасшедший, чтобы не признать это...
Многие винили Цоя в том, что он "о чём вижу, о том пою", но там был простой чёткий смысл, плюс с мистическим отливом,
а нейросеть часто генерирует "топчащуюся на месте смысловую мутотень". (нет "вектора движения мысли", что производит удручающее впечатление на слушателя)
Грёбаная печаль заключается в том, что обещанной мультимодальности в открытой версии для Ollama нет - она должна быть в Google AI Studio, которой я до сих пор не пользовался. Я бы подумал, что дело в несовместимости расширения Page Assist и сервера Ollama, но увы - в описании модели указано, что она принимает только текст. Видимо, админы репозитория Ollama сами её урезали, т.к. она не в курсе о том, что теперь не понимает на вход картинки и аудиозаписи. При попытке их отправить она возвращает глюки и просто придумывает всякую дичь на свободную тему, лишь бы ответить. При этом постоянно пытается отвечать по-английски независимо от языка запроса, чего у обычной Gemma 3 не наблюдалось (она была более адекватна и пыталась следовать запросу в меру возможностей, такого у версии 3N не наблюдается). Несмотря на это, плюс у неё всё же есть: она научилась разбирать текстовые документы (например, PDF, если там содержится именно текст - сканы не понимает, или же обычный txt). Что касается документов office (doc, xls, docx, xlsx и т.д.) - не принимает и считает файлы повреждёнными. Потенциально можно обойти, выгружая их в PDF и скармливая нейросети так, но возможность сомнительная, полезность - тоже. Хотя в определённых моментах может сгодиться.
Можно комбинировать обычную Gemma 3, если надо распознать картинки или быстро сгенерить текст в ответ на запрос или по поиску в интернете, а для разбора PDF использовать версию 3N. В рамках Ollama на обычном компьютере лучших результатов вряд ли можно добиться. Видимо, в данном случае лучше сменить платформу и попробовать что-то другое помимо Ollama, может быть так и сделаю в июле.
Кстати, Gemma 3N с включенным поиском в интернете тексты пишет сносно, однако если указать явно, что текст требуется на русском, источники будет подбирать на нём же. Иначе скорее всего напишет по-английски. При этом качество текста оказывается не сильно лучше, чем у базовой Gemma 3 (которая может без явного промта сама собрать источники на разных языках, но ответ напишет по-русски, что я считаю круто).
В общем пока так, чуда не случилось. Самое главное, чего я ждал от этой версии: транскрибация аудио и видео в базовом режиме (без сторонних инструментов), это в Ollama и не работает. Картинки тоже не понимает, причём та же обычная Gemma в той же Ollama их понимает отлично. Странная ситуация, но уж как есть. Наблюдаем и тестируем.
На hugginface есть инструкция, как развернуть Gemma 3N на pytorch: https://huggingface.co/docs/transformers/main/model_doc/gemma3n Делать это мне пока некогда и негде. В питон я особо не врубаюсь, поэтому может позже попробую, но обещать не буду. Вообще я хотел бы запилить сначала Gemma с RAG (по типу агент помощи и техподдержки), но пока не преуспел даже в деле интеграции её с обычным сайтом, так что инструкция для вас как это сделать будет тоже ещё нескоро. Надеюсь, она всё же будет, но если кто-то желает сделать это раньше меня и отписаться здесь - буду премного благодарен!
P.S.: С 1 июля кардинально обновили Алису. Теперь она отвечает очень быстро и умеет анализировать файлы - текстовые (туда кроме plain txt входят doc, docx и PDF), в том числе видит и анализирует картинки и сканы в файлах. Правильно отвечает в абсолютном большинстве случаев, когда просишь составить выжимку или описать содержимое. К сожалению, недостатки тоже есть - она всё ещё не понимает таблицы, даже CSV. Это плоховато, но видимо со следующим большим обновлением сделают, по крайней мере курс на это прослеживается. Создавать файлы и отдавать их на скачивание тоже не умеет. Однако, теперь уже Алиса в курсе о своих ограничениях и предлагает самостоятельно скопировать результат из чата и вставить его в файл (да, решение так себе, но за неимением лучшего уже что-то, Deepseek кстати тоже так отвечает). Распознавать речь из аудиофайлов и видео, транскрибировать и диаризировать фразы - этого она само собой не умеет и сейчас. Причём перспективы этой возможности сомнительные, ведь у Яндекса есть платный сервис SpeechKit с довольно высокими тарифами, глупо было бы делать бесплатного конкурента. В общем, с этим обновлением полезность Gemma 3N в версии для Ollama устремилась к нулю. Ну разве что в плане локальной обработки данных (если это критично), которые в этом случае никуда с устройства не деваются.
Детализация намного лучше, чем у предыдущей нейросети, но как-то пиксельно. Морда Кибердемона получилась отлично. Интересно, что нейросеть сгенерировала модель только по передней картинке (выбора сторон в ней пока нет). Задняя сторона, на мой взгляд, получилась вполне адекватной. Но есть существенный минус - пока нет поддержки текстур.
BL@CK DE@TH Пиксельность можно убрать сглаживанием, а потом запечь на картах. Главное пропорции чтобы были, а то получится, словно кибердемона катком переехали.
Пробую свои запросы, но учитывая что очередь порой достигает 1к, то ощущение, что модели рисуют где-то в китайском подвале.
А то что нет генерации развёртки довольно грустно.
Детализация намного лучше, чем у предыдущей нейросети, но как-то пиксельно. Морда Кибердемона получилась отлично. Интересно, что нейросеть сгенерировала модель только по передней картинке (выбора сторон в ней пока нет). Задняя сторона, на мой взгляд, получилась вполне адекватной. Но есть существенный минус - пока нет поддержки текстур.
Для 3д-печати выглядит прямо хорошо. Пиксельность может быть артефактом спрайта, стилистику которого нейронка попыталась сохранить. Если туда, допустим, фотку голой бабы засунуть, пиксельность сохраняется?
Если туда, допустим, фотку голой бабы засунуть, пиксельность сохраняется?
Насчёт голых баб не знаю, но попробовал вот такую модель:
Вот это выдал Hunyuan:
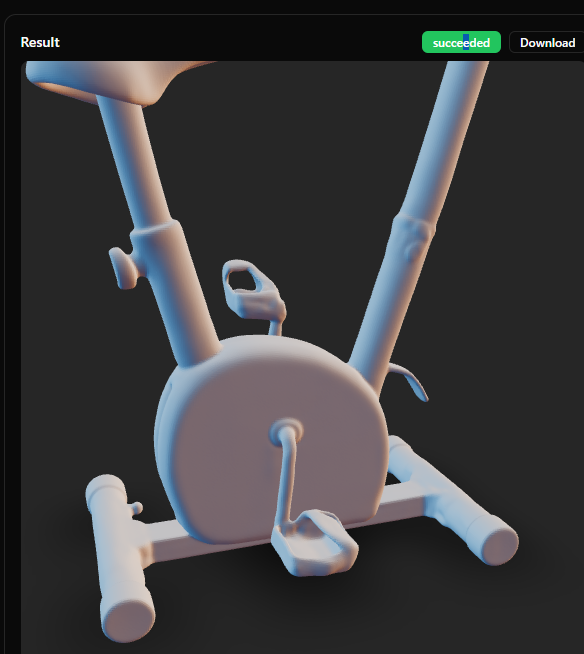
А это - Sparc 3D:
Как видим, Sparc 3D гораздо лучше в детализации и умеет в симметрию, но зачем-то присобачил третью педаль в середину корпуса. Ну и без текстур и сглаживания.
Мда.... а вот у меня что-то не очень получилось. Даже довольно простой запрос оказался малость сложным, хотя стоит признать, что идея искажённого меча мне даже нравится, но всё же это уже самовольничество сетки.
А вот картинку с ректальным дестроером так вообще превратило в китайского дракона с тремя ногами и телом из мозга. Может я что-то упускаю (хотя детализация действительно лучше)?
Согласен. Если бы можно было выбирать несколько картинок, как в Hunyuan, то был бы в разы лучше. Но может ещё допилят со временем. И запекание текстур сделают.
Детализация намного лучше, чем у предыдущей нейросети, но как-то пиксельно. Морда Кибердемона получилась отлично. Интересно, что нейросеть сгенерировала модель только по передней картинке (выбора сторон в ней пока нет). Задняя сторона, на мой взгляд, получилась вполне адекватной. Но есть существенный минус - пока нет поддержки текстур.
Осталось только уменьшить количество полигонов, добавить скелет, текстуру, анимировать и перевести в IQM или MD2.
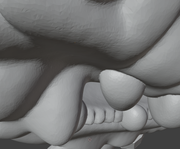
В общем, мне чего-то не сразу пришла в голову идея включить редактор полигонов, а зря... Оказывается модель в настолько высоком разрешении, что прорисовала каждую складочку на теле. Аж при переключении в блендере повисла менюшка. С одной стороны это хорошо для карт, но с другой стороны есть детали, которые не нуждаются в таком количестве полигонов. То есть прям видны порой границы рёбер в цилиндрических деталях, но при редактировании оказывается, что они так же перегружены. В общем не оптимально рисует.
Увеличение показало истину
Вот так выглядит выделенные полигоны
Статистика однако
А вот тут мной был проведён эксперимент. Насколько передаст сетка примитивно нарисованную на коленке хрень без какого смысла с кривыми линиями. Всё же интересно практическое применение.
И опять просто насрало кучей полигнов. Конечно, на то что хотя бы назвать исходник рисунком конечно не претендую, но некоторые детали либо пропущены, либо полностью перестали быть собой.
В общем опять пока рано нам радоваться удобному инструментарию. Безысходность...